
R - reshape2
by Kim
데이터 구조 변경 패키지 reshape2를 이용하여 데이터 구조를 바꾸어보겠습니다. 여기서 말하는 데이터 구조는 데이터 타입(data type)을 말하는 것이 아니라 wide data, long data를 의미합니다.
데이터 구조
wide data
Wide data는 교차 테이블 형식으로 되어있으며 행별, 컬럼별 그룹연산 수행이 가능합니다. 조인이 불가능한 형식이기 때문에 DB에서 선호하는 형식은 아닙니다.
name X1 X2 X3
1 a 10 14 18
2 b 11 15 19
3 c 12 16 20
4 d 13 17 21long data
long data는 DB에서 선호하는 방식의 형식으로 새로운 데이터(관찰대상)에 대한 추가가 비교적 wide data에 비해 쉽습니다. GROUP BY, JOIN 연산이 가능합니다.
name variable value
1 a X1 10
2 b X1 11
3 c X1 12
4 d X1 13
5 a X2 14
6 b X2 15
7 c X2 16
8 d X2 17
9 a X3 18
10 b X3 19
11 c X3 20
12 d X3 21기본 내장 함수
wide data와 long data에 대해 알아보았으니 다음으로는 wide에서 long 혹은 long에서 wide로 바꾸는 함수들에 대해 설명드리려고 합니다.
stack 함수
wide data를 long data로 바꿔주는 함수입니다.
stack(data)unstack 함수
stack의 반대되는 함수로 long data를 wide data로 바꿔주는 함수입니다. unstack 함수의 단점은 행렬 이름에 필요한 행을 가져올 수 없다는 것입니다.
unstack(data, formula)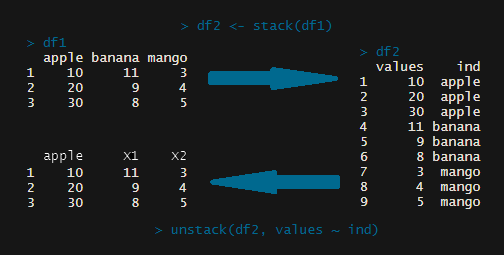
reshape2 패키지
wide에서 long 혹은 long에서 wide로 바꾸는 기본 함수들보다 더 기능이 다양한 함수를 포함하고 있는 reshape2 패키지를 설치해봅니다.
install.package('reshape2')
library(reshape2)melt 함수
wide data를 long data로 바꿔주는 함수입니다. stack과 비슷하지만 고정할 컬럼과 stack을 진행할 컬럼을 정할 수 있습니다. value의 이름과 ind의 이름 또한 인자값 입력으로 설정할 수 있습니다.
melt(data, # 데이터 이름
id.vars, # 고정 컬럼
measuer.vars, # 쌓을 컬럼, 생략하는 경우 고정 컬럼을 제외한 모든 행 stack
value.name, # value 컬럼명
variable.name)# ind 컬럼명dcast 함수
dcast 함수는 long data를 wide data로 바꿔주는 함수로 unstack보다 기능이 많이 있습니다. 비슷한 기능을 가진 함수로 acast도 있습니다만 둘의 차이점은 반환하는 데이터 구조에 차이가 있습니다. dcast는 데이터프레임 형식으로 반환하며 acast는 행렬 형태로 반환합니다.
dcast(data, # 데이터 프레임
formula, # 행 고정, 컬럼 고정
fun.aggregate = NULL, # 요약 함수
value.var = ) # value 컬럼fun.aggregate를 입력하지 않으면 고정 자료들이 겹치는 경우 기본적으로 갯수(length)가 나옵니다. value.var 값을 생략하면 가장 오른쪽에 있는 행렬을 value.var로 이용하게 됩니다.
Subscribe via RSS
{kind=link}