
selenium을 이용한 구글 이미지 가져오기
by Kim
목차
1. selenium
셀레니움은 웹 브라우저를 코드 기반으로 실제 조작하는 방식으로 이용할 수 있는 python의 프레임워크입니다. 사용 목적은 수작업으로 하는 이미지 저장을 코드 작성을 통해 자동화할 수 있기 때문입니다. 웹 브라우저를 통해 직접 접속하여 이미지를 수집하기 때문에 안티 크롤링에 대한 걱정 또한 없습니다.
다양한 브라우저(Chrome, Firefox 등), 다양한 언어(Java, Python, PHP 등)를 지원하는데 이 글에서는 크롬 기반으로 진행해보겠습니다. 웹 크롤링을 하기 위해서는 html의 구조에 대해서 익숙해야 쉽게 접근할 수 있으니 html에 대한 내용이 어려우신 분들은 html에 대한 추가적인 공부를 하는 것을 권장합니다.
2. 기본 환경을 위한 다운로드
2-1) 가상환경 설정
여러 버전의 Python을 실행하기 위해 가상환경 설정을 했는데 버전 하나로만 실행하시는 분들은 바로 아래 단계로 넘어가면 됩니다.
venv를 이용한 가상환경을 만들어봅니다. python -m venv 뒤에는 본인이 원하는 이름을 입력하면 됩니다.
python -m venv selenium
위 코드를 실행하면 selenium 이라는 폴더가 생성되면서 그 안에 가상 환경이 만들어집니다. 해당 폴더에 있는 Scripts 로 들어가서 activate를 실행하면 해당 가상 환경에서 python을 실행할 수 있습니다.
cd selenium/Scripts
activate
2-2 selenium 설치
가상 환경에서 pip install selenium 을 입력 후 실행하면 됩니다.

2-3) 크롬 드라이버 설치
구글에서 크롬 드라이버를 검색 후 홈페이지에 들어갑니다. 현재 사용하고 있는 크롬 브라우저의 버전을 확인 후 다운로드하면 됩니다. 현재 버전을 확인하려면 크롬 설정에 들어가서 Chrome 정보를 클릭해서 확인할 수 있습니다.
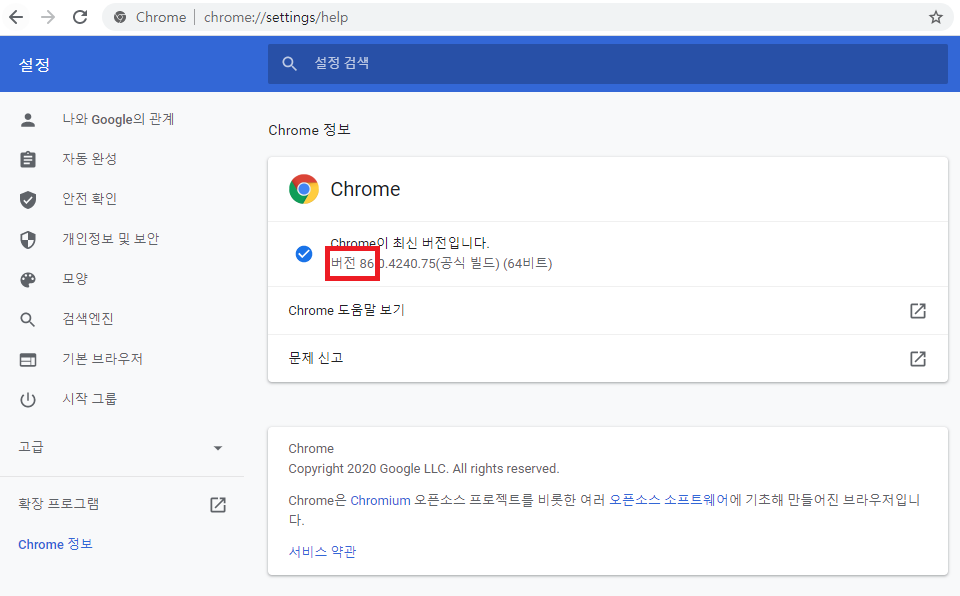
버전 확인 후 다시 크롬 드라이버 홈페이지에서 자신의 버전과 맞는 링크를 클릭 후 다운로드 하시면 됩니다. 윈도우에서 실행할 것이기 때문에 저는 윈도우 버전을 받았습니다.
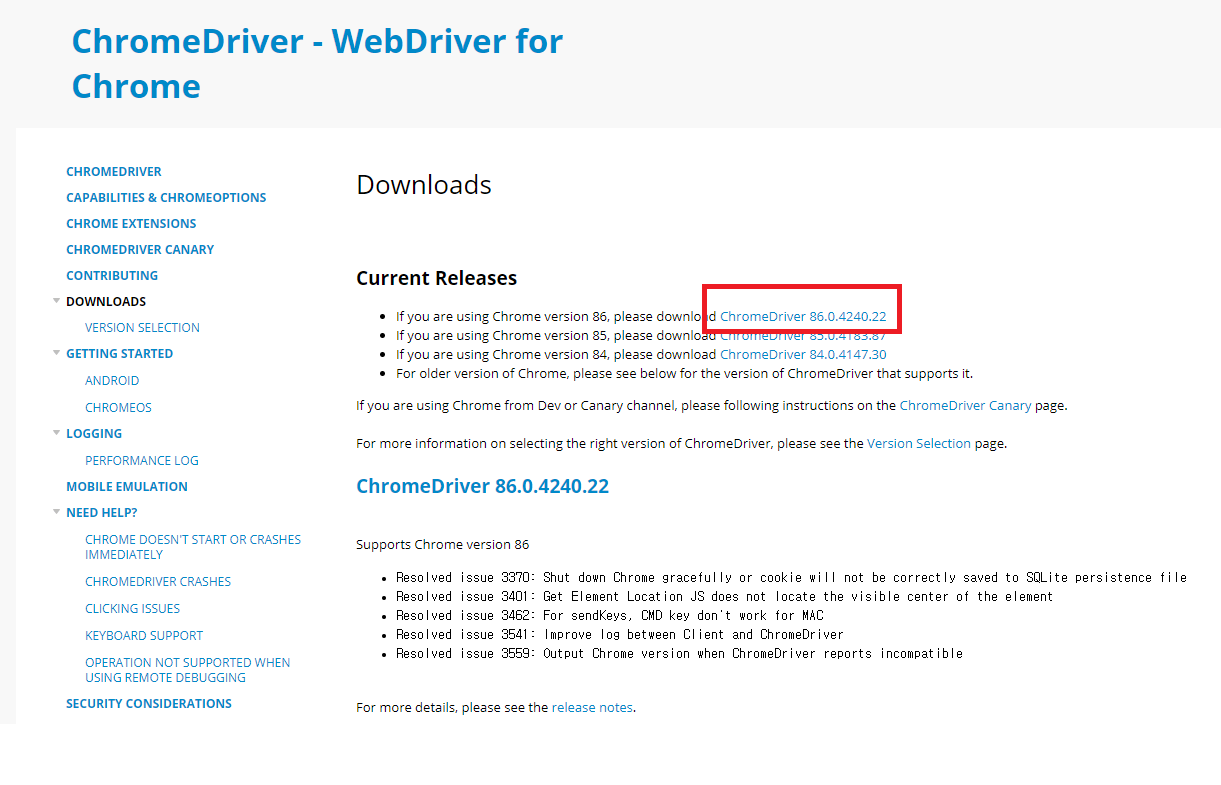
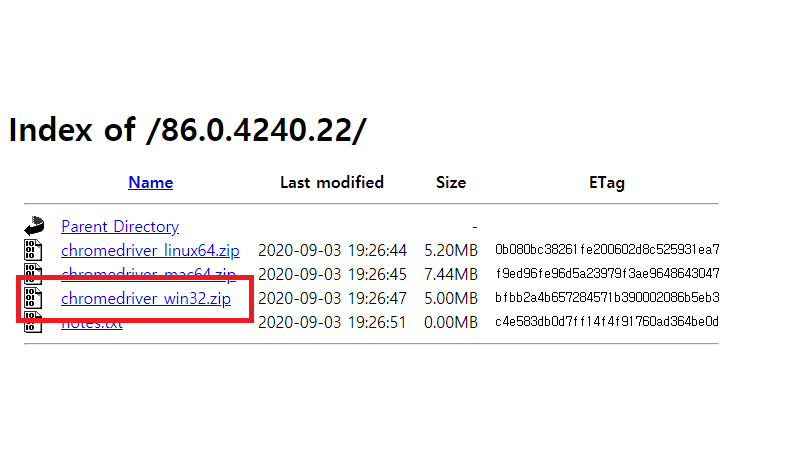
zip 파일을 다운로드했으면 압축을 풀고 아까 만들었던 selenium 폴더로 exe 파일을 옮기면 모든 준비가 완료됩니다.
3. 이미지 크롤링 시도
셀레니움을 실행하기 위한 환경이 완성이 되었습니다. 이제 실행해보도록 합시다.
3-1 selenium 테스트
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.google.com')
browser.close()큰 이상이 없으면 크롬 브라우저가 실행되어 구글 메인화면이 나온 뒤 브라우저가 자동으로 종료되었을 것입니다.
3-2) 구글에서 dog 이미지 검색
browser.get 안에 기존 구글 주소 대신에 구글 이미지 주소를 입력해봅시다. 키워드는 dog로 설정했습니다.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
browser = webdriver.Chrome()
browser.get('https://www.google.co.kr/imghp?hl=ko&tab=wi&ogbl')
keyword = "dog"
# 이미지 검색
ele = browser.find_element_by_css_selector(".gLFyf.gsfi")
ele.send_keys(keyword)
ele.send_keys(Keys.RETURN)
browser.close()이번에는 키를 입력하는 모듈을 추가로 불러왔습니다. 코드의 실행 순서는 이렇습니다. 일단 구글 이미지 페이지에 들어가서 검색 창(css = “gLFyf.gsfi”)을 찾아서 그 안에 키워드인 “dog”를 입력 후 엔터버튼을 실행(Keys.RETURN)합니다. 위에서 html 구조에 대해 익숙해야 한다는 얘기를 했는데 이 과정에서 검색 창을 선택하는 작업과 관련이 있기 때문입니다.
검색 창이 어떤 태그를 가지고 있는지 알아야 코드 실행만으로 자동으로 검색 창을 선택할 수 있습니다. 태그를 알아보기 위해 구글 이미지 화면에서 F12를 눌러봅니다. 그러면 오른쪽 화면에 개발자 모드가 열립니다. 개발자 모드 맨 위 왼쪽 버튼(ctrl+shift+c)를 누르고 검색 창 위에 커서를 갖다대면 아래 이미지처럼 해당 위치에 대한 정보가 출력됩니다.
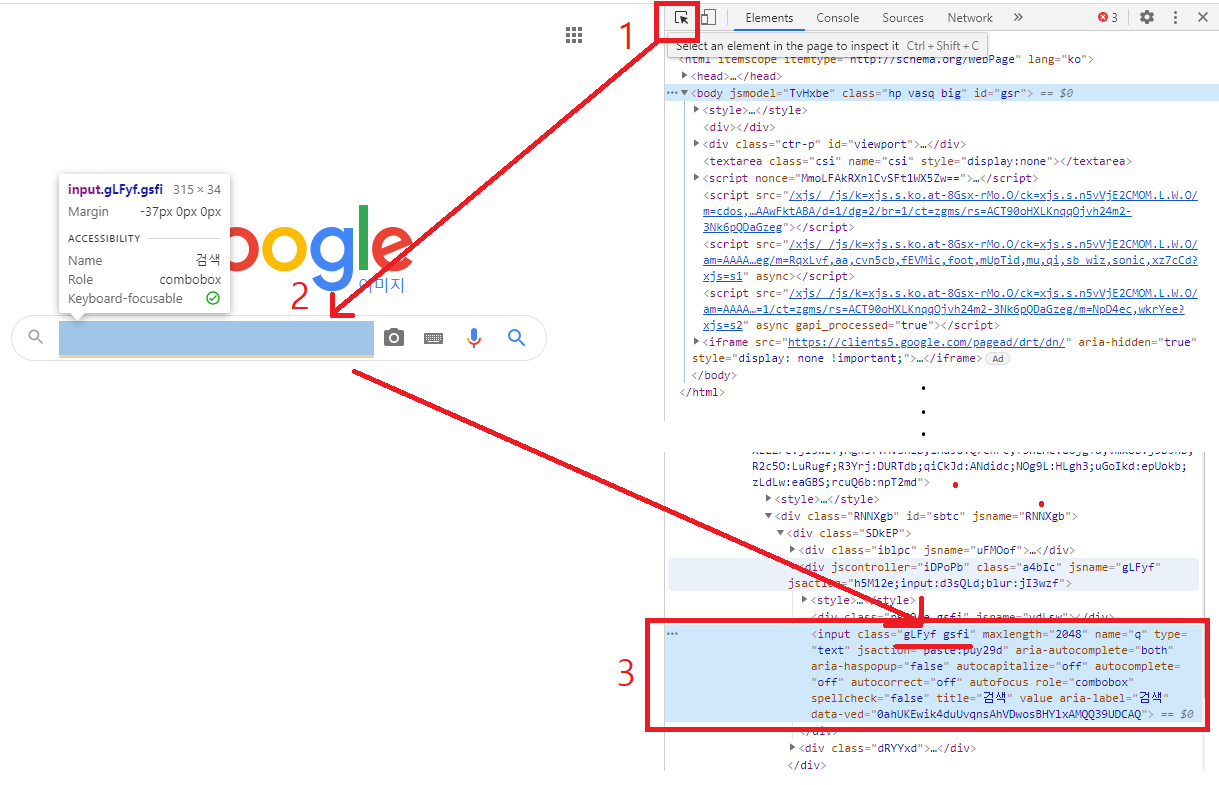
3-3) 검색 후 이미지 저장
검색 후 나온 이미지들을 저장해보도록 합니다. 위와 마찬가지로 개발자 모드에서 이미지에 해당하는 태그를 찾고(css = “wXeWr.islib.nfEiy.mM5pbd”), 각 이미지에서 (css = “n3VNCb”) 이미지 링크(src = “이미지_링크”)를 얻은 후 해당 이미지를 저장하게 됩니다.
잔렉으로 인해 코드가 실행되다가 꼬일 수 있으니 time 모듈을 불러와서 이미지를 불러오는 간격을 2초정도 설정했습니다.(time.sleep(2))
이미지 저장시 파일 이름은 f string을 이용해 dog_숫자.jpg 형식으로 저장합니다.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import urllib.request
import time
browser = webdriver.Chrome()
browser.get('https://www.google.co.kr/imghp?hl=ko&tab=wi&ogbl')
keyword = "dog"
ele = browser.find_element_by_css_selector(".gLFyf.gsfi")
ele.send_keys(keyword)
ele.send_keys(Keys.RETURN)
# 이미지 저장
images = browser.find_elements_by_css_selector(".wXeWr.islib.nfEiy.mM5pbd")
for i in range(len(images)):
images[i].click()
time.sleep(2)
imgUrl= browser.find_element_by_css_selector(".n3VNCb").get_attribute("src")
urllib.request.urlretrieve(imgUrl, f"{keyword}_{i}.jpg")
browser.close()3-4) 검색 후 모든 이미지 저장
위에서 이미지 저장을 했을 때 50개밖에 저장되지 않은 것을 확인할 수 있습니다. 그 이유는 스크롤에 대한 것을 고려하지 않았기 때문입니다. 따라서 스크롤을 내리는 코드를 추가하여 dog를 검색했을 떄 구글에서 나오는 모든 이미지를 저장해보도록 수정했습니다. 3-3)에서의 코드에서 스크롤을 계속 내리고 결과 더 보기가 나오면 클릭하여 이미지를 계속 불러오고 해당 버튼이 더 이상 뜨지 않으면 페이지에 나타난 모든 이미지를 크롤링 한 후 브라우저가 종료됩니다.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import urllib.request
import time
browser = webdriver.Chrome()
browser.get('https://www.google.co.kr/imghp?hl=ko&tab=wi&ogbl')
keyword = "dog"
ele = browser.find_element_by_css_selector(".gLFyf.gsfi")
ele.send_keys(keyword)
ele.send_keys(Keys.RETURN)
# 스크롤 내리기
# 스크롤 내린 후 멈추는 시간
SCROLL_PAUSE_SEC = 1
# 스크롤 높이 가져옴
last_height = browser.execute_script("return document.body.scrollHeight")
while True:
# 끝까지 스크롤 다운
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# 1초 대기
time.sleep(SCROLL_PAUSE_SEC)
# 스크롤 다운 후 스크롤 높이 다시 가져옴
new_height = browser.execute_script("return document.body.scrollHeight")
if new_height == last_height:
try :
browser.find_element_by_xpath("/html/body/div[2]/c-wiz/div[3]/div[1]/div/div/div/div/div[5]/input").click()
except :
break
last_height = new_height
images = browser.find_elements_by_css_selector(".wXeWr.islib.nfEiy.mM5pbd")
for i in range(len(images)):
images[i].click()
time.sleep(2)
imgUrl= browser.find_element_by_css_selector(".n3VNCb").get_attribute("src")
urllib.request.urlretrieve(imgUrl, f"{keyword}_{i}.jpg")
browser.close()Subscribe via RSS
{kind=link}