
beautifulsoup을 이용한 웹 크롤링
by Kim
웹 스크레이핑과 크롤링
웹 스크레이핑(scraping)은 html, css기반의 웹 페이지에서 파싱으로 필요한 정보만을 가져오는 것을 말합니다. 이런 활동을 정기적으로 하는 것을 웹 크롤링이라고 합니다. Python으로 하는 스크레이핑의 장점은 일일히 사이트 뒤져가면서 복사하는 것을 코드가 대신 자동으로 해주기 때문입니다.
웹 페이지의 구조는 언제 변할지 모르는 것이기 때문에 예전에 되었던 코드도 나중에 무용지물이 되는 경우가 많습니다. 따라서 스크레이핑 작업을 할 때는 기존의 코드를 그대로 복사하기보다는 어떤 과정으로 진행되는지 알아둬야할 필요가 있습니다.
urllib 이해하기
url library(urllib)은 입력한 링크(url)의 페이지 내용을 저장합니다.
# import 라이브러리 등록
import urllib.request
# 변수 선언
url = "접속할 URL"
Savefile = "저장할 파일명"
urllib.request.urlretrieve(url, savefile)서울시 홈페이지 가져오기
아래 코드는 서울시 홈페이지 메인을 가져와 파일 형태로 만드는 코드입니다.
import urllib.request
url = "https://www.seoul.go.kr/main/index.jsp"
req = urllib.request
mem = req.urlopen(url).read()
# euc-kr, utf-8
decodeMem = mem.decode("utf-8")
# 파일로 만들기
with open("seoul.html", mode="wb") as f:
f.write(mem)
print("파일 다운 완료")utf-8은 유니코드로 바꿔주는 인코딩 코드로 주로 한글을 인코딩할 때 쓰입니다. 그대로 가져오면 한 줄 띄우기, 한글 등의 글자들이 보기 편한 방식으로 불러올 수 없기 때문에 decode 메소드로 불러옵니다.
아래는 서울시 검색창에 뉴딜일자리를 검색한 페이지를 가져오는 코드입니다.
import urllib.request
uri = "https://newsearch.seoul.go.kr/ksearch/search.do"
values = {"kwd":"뉴딜일자리"}
dataEncode = urllib.parse.urlencode(values)
url = uri + "?" + dataEncode
data = urllib.request.urlopen(url).read()
with open("seoul_quiz2.html", mode="w") as f:
f.write(data.decode("utf-8"))
print("파일 다운 완료")아래 칸에 웹 페이지 주소(url)의 형식이 어떻게 되어 있는지 간단하게 나눴습니다.
물음표(?) 앞까지는 기본 식별자(uri)이며, 뒤 내용부터 하위 옵션이라고 볼 수 있습니다. 즉 검색어가 바뀌면 앞의 uri는 그대로고 ? 뒤에만 바뀝니다.
BeautifulSoup 이해하기
뷰티풀 수프(BeautifulSoup)는 html 및 XML 파일에서 원하는 데이터를 가져올 수 있게하는 Python 라이브러리입니다. 짧은 예제를 통해서 살펴보도록 합시다.
from bs4 import BeautifulSoup
html = """
<html><body>
<h1>스크래핑이란?</h1>
<p>웹 페이지를 분석하는 것</p>
<p>원하는 부분을 추출하는 것</p>
</body></html>
"""
soup = BeautifulSoup(html, "html.parser")
print(soup.html.body.h1 )
print(soup.html.body.h1.string)html이라는 이름의 변수의 내용을 html방식으로 파싱을 한 후 soup라는 변수에 입력하였습니다. 그리고나서 soup에서 body 안의 h1 부분만 프린트를 하였습니다.
웹 페이지 소스는 html로 되어 있기 때문에 이런 방식으로 진행을 해보았습니다. 이번에는 네이버의 웹페이지 코드를 이용하여 필요한 정보를 가져옵시다.
네이버에서 가져오기
네이버 시장지표에서 미국 환율을 긁어오겠습니다.
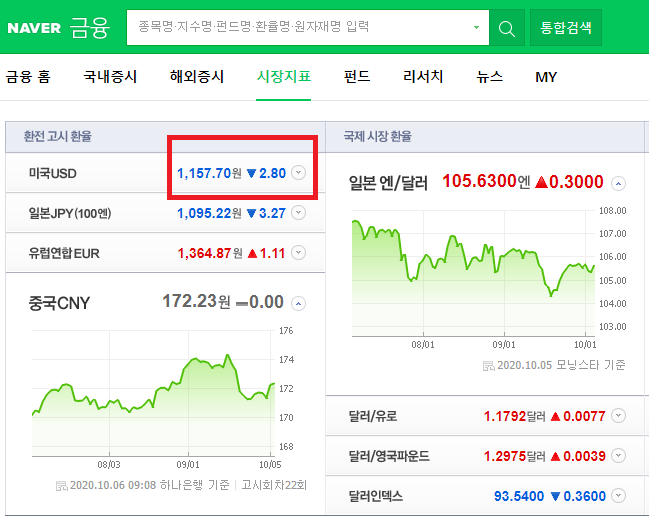
from bs4 import BeautifulSoup
import urllib.request as req
uri = "https://finance.naver.com/marketindex/"
html = req.urlopen(url)
soup = BeautifulSoup(html, "html.parser")
# Value 추출
value = soup.select_one("span.value")
print(value, ":", value.string)
# p 태그 추출 : select 여러개 데이터 추출
values = soup.select("span.value")
for v in values:
print(v, ":", v.string)html형식의 파일에서 요소를 추출하는 메소드는 두 가지가 있습니다. select_one은 요소 하나만 추출하고 select는 여러 개의 리스트를 추출합니다. 조심해야할 사항이 있는데 select로 불러올 때는 하나의 값을 추출해도 리스트로 가져오기 때문에 변수 사용시 자료 구조의 문제로 원하는 코드가 실행이 안 될 수도 있습니다. 아래 다음 뉴스 내용 가져오기에서 이런 문제를 해결하는 방법을 명시해두었습니다.
다음에는 국제 시장 환율에서 상승하는 환율만 가져오는 실습을 해봅시다.
from bs4 import BeautifulSoup
import urllib.request as req
url = "https://finance.naver.com/marketindex/"
html = req.urlopen(url)
soup = BeautifulSoup(html, "html.parser")
# id가 worldExchangeList인 값 추출 후 li가 a
values = soup.select("#worldExchangeList li a")
for v in values:
div = v.find("div","head_info point_up")
if div is None :
continue
moneyName = v.h3.span.string
money = v.find("div").find("span","value").string
print(moneyName + money)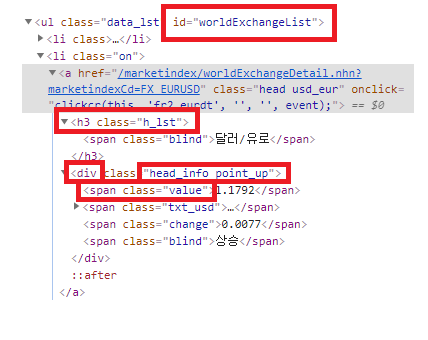
국제 시장 환율을 담는 부분의 id가 worldExchangeList인 부분 내에서 li-a 부분만 가져왔습니다. 이들을 values에 넣고 하나 하나씩 살펴보면서 div 들을 살펴본 후 head_info point_up(네이버 시장지표에서 지수 증가시 부여되는 id)에 해당하지 않으면 for 문을 넘기는 방식으로 진행하였습니다. 지표의 이름은 h3안에 span에서 가져와 moneyName라는 변수로 생성하고 현재 환율은 div 안에 span이 value인 부분을 money로 가져와 만들었습니다.
다음 뉴스 내용 가져오기
이번에는 다음 뉴스에서 열독률 높은 뉴스 5개의 기사 내용을 스크레이핑 해보겠습니다.
1. 열독률 높은 뉴스 5개의 기사들의 주소만 가져오기
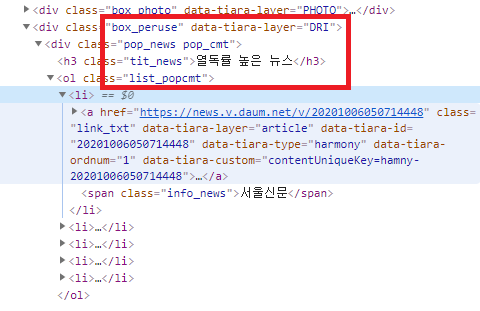
from bs4 import BeautifulSoup
import urllib.request as req
def getURLInfo(url, tag):
html = req.urlopen(url)
soup = BeautifulSoup(html, "html.parser")
return soup.select(tag)
url = "https://news.daum.net/"
tag = "div.box_peruse div.pop_news.pop_cmt ol.list_popcmt li"
values = getURLInfo(url,tag)
# a 안의 href 특성 읽기
for v in values:
print(v.a.attrs["href"])
Out:
https://news.v.daum.net/v/## #(기사 번호 마스킹)
https://news.v.daum.net/v/##
https://news.v.daum.net/v/##
https://news.v.daum.net/v/##
https://news.v.daum.net/v/##2.기사 내용 가져오기
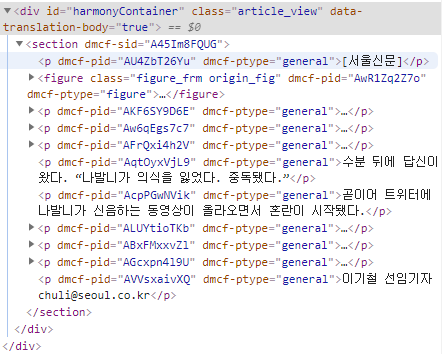
from bs4 import BeautifulSoup
import urllib.request as req
import time # 주소 입력에 대한 시간 제한을 위해 불러옴
# 함수 생성 : 입력한 url의 정보를 태그에 맞춰서 파싱
def getURLInfo(url, tag):
html = req.urlopen(url)
soup = BeautifulSoup(html, "html.parser")
return soup.select(tag)
url = "https://news.daum.net/"
tag = "div.box_peruse div.pop_news.pop_cmt ol.list_popcmt li"
values = getURLInfo(url,tag)
for v in values:
articleUrl = v.a.attrs["href"]
articleTag = "section"
data = getURLInfo(articleUrl,articleTag)
print(data[0].text)
# [0] : 리스트 형식으로 되어 있어 괄호 제거
# text : 괄호 제거 후 후 내용만 출력
time.sleep(3) # 3초 딜레이다음 뉴스 메인 url에서 열독률 높은 기사의 링크 5개를 추출하고, 각 링크에서 본문 내용만 가져오는 코드입니다. 페이지 내용을 파싱하는 과정이 두 번 이상이기 때문에 이런 작업을 사용자 정의 함수로 정의하여 구문을 단순하게 만들었습니다.
이번에 사용한 코드는 단지 5개의 기사를 불러오기 때문에 큰 문제가 없지만 수 백, 수 천건의 대량의 웹 페이지 정보를 가져오는 경우 디도스와 같은 서버에 대한 공격으로 받아들일 수 있습니다. 따라서 time을 불러와서 기사 하나의 내용을 불러온 후 3초의 딜레이를 주었습니다.
우회 접속(안티 크롤링 방지)
광고 수입으로 돈을 버는 사이트의 경우 웹 브라우저를 이용하지 않는 웹 접속을 막는 경우가 있습니다. 네이버 뉴스같은 경우 이전까지 배운 내용으로 크롤링을 시도하면 접속을 차단하기도 합니다. 그렇기 때문에 우회 접속을 도와주는 requests를 이용하여 웹 페이지를 크롤링 해보도록 하겠습니다.
from bs4 import BeautifulSoup
import requests
import time
def getURLInfo(url,tag):
urlHeader=requests.get(url,headers={'User-Agent':'Mozilla/5.0'})
html=BeautifulSoup(urlHeader.text,"html.parser")
return html.select(tag)
# 네이버 경제 쪽 헤드라인 기사들 가져오기
url="https://news.naver.com/main/main.nhn?mode=LSD&mid=shm&sid1=101"
tag="div.cluster div.cluster_group._cluster_content div.cluster_body ul li div.cluster_text a"
headline=getURLInfo(url,tag)
for news in headline:
print(news.text)
articleURL=news.attrs["href"]
articleTag="#articleBodyContents"
data=getURLInfo(articleURL,articleTag)
#data가 리스트 형식이라 직접적으로 .text를 사용할 수 없음
print(data[0].text)
print("------------------------")
#break (첫 번째 테스트 후 주석 처리)
time.sleep(1)웹 이용시에 크롬, 파이어폭스같은 브라우저를 포함한 모든 소프트웨어는 User-agent를 갖습니다. User-agent의 정보를 통해 “나는 이 프로그램을 이용하여 웹에 접속하였다”를 증명합니다. 그래서 이 코드는 일반 웹 브라우저의 정보를 User-agent에 넣고 웹 브라우저를 이용해 접속한 것처럼 보이는 우회 방식을 이용한 크롤링입니다. 우회하여 가져온 html 문서에서 이전에 파싱을 했듯이 원하는 부분을 추출하면 됩니다.
Subscribe via RSS
{kind=link}