
pandas - DataFrame (2)
by Kim
목차
이번 글까지는 데이터 프레임에서 사용할 수 있는 함수와 메서드 등에 중심을 둘 것입니다. 앞에서 배운 내용보다 약간 더 심화된 내용이니 이해가 어려우신 분들은 앞의 내용을 충분히 숙지하시는 것을 권장드립니다. 다음 글에서는 앞에서 다루었던 내용에 대한 실습문제를 추가할 예정입니다.
10. 외부 파일 불러오기
이번에는 외부 파일을 불러오는 함수를 사용해보도록 하겠습니다. Python을 껐다가 킨 분들은 프로필을 다시 불러옵시다.
run profile1csv 파일 불러오기 (pd.read_csv)
pandas 불러온 후 원하는 파일을 불러오는 함수를 사용해보도록 하겠습니다. 우선, csv 파일을 불러오는 연습을 해봅시다. 함수를 사용하기 전에 필요한 예제 파일을 아래 링크를 통해 받아주세요.
파일을 받아보셨으면 기본 디렉토리로 옮기셔야 파일 이름만으로 불러올 수 있기 때문에 편의상 파일 위치를 옮깁니다. 그리고나서, 아래 코드를 보면서 함수에 어떤 옵션들이 있는지 알아봅시다.
pd.read_csv(
file, # 파일 이름
dtype=None, # 컬럼의 데이터 형 입력, 딕셔너리 형태로 개별 입력 가능
engine=None, # 파싱 엔진, 오류 생길때 'python'으로 설정하면 해결되기도 함
skiprows=None, # 제외할 행 입력
encoding=None # 인코딩 옵션 (유니코드 등)
)주로 쓰는 옵션들은 이 정도입니다.
file에는 파일의 이름을 적으면 됩니다. 기본 디렉터리에 있는 경우는 그렇고 기본 디렉토리에 없는 파일을 불러올 때는 파일의 경로를 모두 적어야합니다.
dtype 은 불러올 데이터의 데이터 형을 정해서 가져오는 것입니다. 예를 들어 숫자로만 되어있는 파일을 문자열 형으로 바꿔서 불러올 수 있습니다.
engine은 파싱 엔진으로 이에 대한 설명은 추가적인 공부 이후 추가하도록 하겠습니다. 파일을 불러올 때 문제가 생기는 경우 engine = 'python'으로 불러오면 제대로 불러와지는 경우가 있어서 개인적으로 자주 사용하는 옵션입니다.
skiprows는 위부터 시작해서 불러오지 않을 행의 갯수를 지정하는 옵션입니다. 깨끗하지 않은 파일들은 윗 부분에 필요없는 자료들이 있기 때문에 이 방식을 사용하면 추가 작업없이 불러오면서 제거가 됩니다.
encoding 옵션은 문자 인코딩 시스템을 정하는 옵션으로 일반적으로는 유니코드를 인코딩하는 'utf-8'을 사용합니다. 다만 ‘utf-8’에서 지원하지 않는 한글 글자를 지원하기 위해 'cp949'라는 인코딩이 이후 생겼는데 동일 파일에 대해서 인코딩 옵션이 다르면 불러올 때 오류가 발생하게 됩니다. 그래서 파일 불러올 때 오류 발생 시 encoding = 'cp949'를 입력하면 인코딩 오류가 해결되기도 합니다.
대부분의 상황에서는 file이나 encoding 말고는 생략해도 되는 옵션이지만 데이터가 완전 청결할 때의 일이고 여러 원인으로 인하여 파일을 제대로 불러올 수 없는 경우가 있습니다. 그래서 옵션을 잘 설정하는 게 중요한데 이 글에서는 가벼운 옵션들만 적용해보도록 하겠습니다. 위 코드에서는 모든 옵션을 설명드린것은 아니고, 추가적인 옵션 정보를 얻고 싶은 분들은 아래 추가 옵션 설명을 통해 확인해보시거나 pandas에서 제공하는 참조 페이지(영어)를 보면 됩니다.
(+) 추가 옵션 설명
pd.read_csv(
file, # 파일 이름
sep=',', # 분리 구분자
header='infer', # 첫 행을 컬럼으로 할지 정하는 옵션
names=None, # 컬럼 이름
index_col=None, # 인덱스로 정할 컬럼 선택
usecols=None, # 불러올 컬럼
dtype=None, # 컬럼의 데이터 형 입력, 딕셔너리 형태로 개별 입력 가능
engine=None, # 파싱 엔진, 오류 생길때 'python'으로 설정하면 해결되기도 함
skiprows=None, # 제외할 행 입력
nrows=None, # 불러올 행 갯수 입력
na_values=None, # NaN으로 바꿀 문자열 입력
parse_dates=False, # 날짜 파싱할 컬럼 입력, 리스트, 딕셔너리 형식으로 전달
encoding=None # 인코딩 옵션 (유니코드 등)
)파일을 받고, 위 코드를 확인하셨으면 실제로 파일을 불러봅시다.
pd.read_csv(
'read_test.csv',
engine = 'python'
)옵션을 크게 건드리지 않고 함수를 사용하면 파일을 원래 그대로 불러오게 됩니다. 예제 파일의 경우 data 컬럼이 날짜를 나타내는 것 같아 보이는데 불러오는 동시에 날짜 형식으로 불러오는 parse_dates 옵션을 사용해서 다시 불러봅시다.
pd.read_csv(
'read_test.csv',
engine = 'python'
parse_dates = ['date']
# parse_dates = 'date'라고 입력하면 형식 에러가 발생합니다.
)두 코드로 불러온 데이터 프레임을 아래 이미지에서 한번 비교해봅시다.
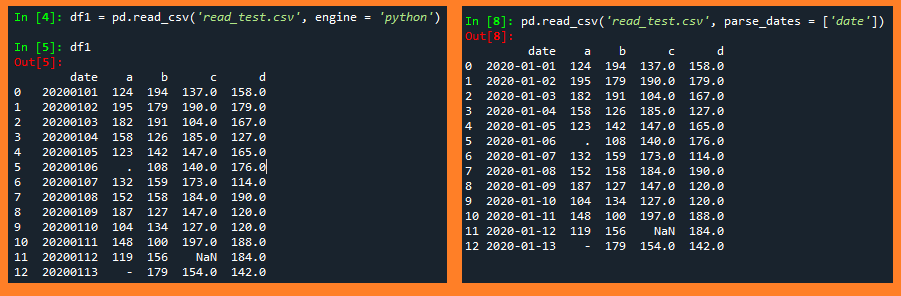
txt 불러오기
아래 txt 파일을 받은 후 기본 디렉토리로 옮깁시다.
그리고 간단히 불러옵시다.
arr1 = np.loadtxt('test3.txt')방금 불러온 텍스트 파일은 연도별(행/2000 ~ 2013년) 연령대별(열/20,30,40,50,60대 이상) 실업률입니다. 복습 차원에서 이 배열을 데이터 프레임으로 바꾼 후 인덱스와 행/열에 맞게 간단한 전처리를 직접 해봅시다.
답 예시
df2 = DataFrame(arr1)
df2.index = ['20%02d년' % i for i in range(0,14)]
#df2.index = [f'20{i:#02d}년' for i in range(0,14)]
df2.columns = ['20대','30대','40대','50대','60대이상']11. 적용 메소드
적용 메소드는 함수의 반복처리를 도와주는 메소드로 방식은 앞에서 다룬 산술 연산에서의 메소드와 비슷하지만 산술 연산 말고도 각 원소에 사용자 정의 함수를 사용할 수 있다는 강점이 있습니다. 문자열 데이터를 원하는 포맷으로 바꾼다거나 천 단위 쉼표(,)를 제거하는 함수를 적용하여 숫자형 데이터로 바꾼다거나 하는 식으로 많은 양의 Value들을 전처리 하는데 큰 도움이 됩니다.
적용 메소드는 크게 세 가지가 있으며 앞에서도 사용했던 map, 2차원 구조에 행/열 단위로 적용할 수 있는 apply 그리고 모든 원소에 각각 적용하는 applymap이 있습니다.
1) map
- 1차원 구조(Series, index object)에 적용 가능,원소별 적용
- 함수와 메소드 둘다 존재
| 함수 | 메소드 | |
|---|---|---|
| 문법 | map(func, *iterables) | df.col.map(arg, na_action = None) |
| 추가 인자 전달 여부 | 가능 | 불가 |
위에서 만든 데이터 프레임 df2를 이용하여 간단한 문제를 풀어봅시다.
예제 1) 모든 년도의 30대 실업률을 소숫점 두자리 포맷으로 변경하시오.
정답
df2.loc[:,'30대'].map(lambda x : '%.2f' % x)2) apply
- 2차원 구조에 적용가능하고, 행별 또는 컬럼별 적용
- 적용함수에 Series 형태로 데이터를 전달하기 때문에 그룹 함수와 어울림
- df1.apply(func,axis=0,**kwds) : 내장 함수가 필요로 하는 추가 인자 전달 가능
예제 2) 연령대 별 전년도 실업률의 평균을 구하시오.
정답
df2.apply('mean', axis = 0)3) applymap
- 2차원 구조에 적용 가능, 원소별 적용
- df1.applymap(func) : 함수가 필요로 하는 추가 인자 전달 불가
예제 3) 예제 1을 모든 원소에 대해 적용해보시오.
정답
df2.applymap(lambda x : '%.2f' % x)12. 치환 메소드(replace)
다음으로는 특정 값을 원하는 값으로 바꾸는 replace 메소드와 기타 값 치환 메소드에 대해 알아보겠습니다.
1. 문자열 메소드 형태(기본 python 제공)
'abc'.replace('a','A')
- 문자열 치환이므로 첫 번째, 두번째 인자에는 문자열만 올 수 있음
- 숫자, NA값의 치환 및 불가
- 벡터연산 불가 => 적용함수 필요
2. pandas 값치환 메소드 형태(pandas 제공)
df1.replace(100,1000)
-첫번째 인자와 정확히 일치하는 값을 찾아 두번째 인자로 리턴 -값 치환이므로 숫자, NA 치환 및 리턴 가능 -벡터 연산 가능(Series, DataFrame적용 가능)
3. pandas 문자열 메소드 형태(pandas 제공)
Series(['abc','bcd']).str.replace('a','A')
- 문자열의 일부(패턴) 치환만 가능, 값 치환 불가
- 문자열 메소드 형태와 기능 동일, 벡터연산 가능(Series에만 적용 가능)
4. NA 치환 메소드
| 설명 | |
|---|---|
| df3.replace(NA,0) | pandas 값 치환 메소드 |
| df3.fillna(0) | pandas NA 전용 치환 메소드 |
| np.where(df3==NA,0,df3) | numpy |
13. 인덱스 추가 내용
인덱스에 대하여 추가적으로 다루도록 하겠습니다. 최댓/최솟값을 갖는 인덱스 찾는 메소드, 행 번호가 여러 개인 멀티 인덱스(multi index), 데이터 프레임 안의 행을 인덱스로 바꾸는 set_index 메소드 등 여러 개념들이 있습니다.
1) 최댓/최솟값 찾는 메소드
축 번호(axis)를 사용하여 행별 열별 최대/최소를 갖는 위치값을 리턴합니다.
1. numpy의 argmax/argmin
- array, Series 사용가능, DataFrame에는 사용이 불가능한 메소드
2. pandas의 idxmax, idxmin
- Series, Dataframe 적용 가능, array에는 사용이 불가능한 메소드
예시)
# 배열 생성
arr2 = np.array([[3,2,9],[10,2,1],[2,4,3]])
# 동일 Value의 데이터 프레임 생성
df1 = DataFrame(arr1)
# 배열 : 행 방향으로 최댓값 가진 인덱스 출력
arr2.argmax(axis=0)
Out[59]: array([1, 2, 0], dtype=int64)
# 배열 : 열 방향으로 최댓값 가진 인덱스 출력
arr2.argmax(axis=1)
Out[60]: array([2, 0, 1], dtype=int64)
# 시리즈 : 최댓값 가진 인덱스 출력
df1.iloc[:,0].argmax()
Out[61]: 1
df1.iloc[:,0].idxmax()
Out[62]: 1
# 데이터프레임 : 행 방향으로 최댓값 가진 인덱스 출력
df1.argmax(axis = 0)
AttributeError: 'DataFrame' object has no attribute 'argmax'
df1.idxmax(axis = 0)
Out[64]:
0 1
1 2
2 0
dtype: int642) 멀티 인덱스(multi_index)
멀티 인덱스는 한 행에 인덱스가 하나만 있는 것이 아닌 여러 개가 있는 것을 말합니다. 행들의 인덱스끼리 계층(level) 구조를 띄고 있습니다. 멀티 인덱스 구조의 데이터프레임을 만들어보면서 어떤 구조인지 살펴봅시다.
df1 = DataFrame(np.arange(1,9).reshape(4,2))
df1.index = [['A','A','B','B'],['a','b','a','b']]
df1
Out[32]:
0 1
A a 1 2
b 3 4
B a 5 6
b 7 8위 데이터 프레임은 상위 계층(level = 0)의 인덱스가 ['A','B']로 되어있고 하위 계층(level = 1)의 인덱스가 ['a','b']로 되어있습니다.
예제 파일을 통해 멀티 인덱스로 구성된 파일을 어떻게 전처리하는지 살펴보도록 하겠습니다. 바로 다음 항목인 멀티 인덱스에서 사용할 데이터 프레임이니 꼭 실행하셔야 합니다.
# 파일 불러오기
df3 = pd.read_csv('multi_index.csv', encoding = 'cp949')
# 인덱스
df3.iloc[:,0] = df3.iloc[:,0].fillna(method='ffill')
df3 = df3.set_index(['Unnamed: 0','Unnamed: 1'])
# 컬럼
a1 = df3.columns.map(lambda x : np.where('Unnamed' in x , NA, x))
a1 # np.where의 결과가 array이므로 하나의 데이터타입만 허용, NaN이 문자형으로 출력
a1 = df3.columns.map(lambda x : NA if 'Unnamed' in x else x)
df3.columns = Series(a1).fillna(method = 'ffill')
# multi index
df3.columns = [list(df3.columns), list(df3.iloc[0,:])]
#df3.index.names = ['지역','AB']
#df3.columns.names = ['상품','정보']3) 멀티 인덱스 색인 (xs)
기존의 loc, iloc는 기본적으로는 상위 레벨의 값을 색인합니다. 튜플 형태로 전달시 하위 레벨의 값도 색인 가능합니다만, 문제는 하위 레벨의 인덱스에 대해서만 색인하는 것은 지원하지 않습니다. 이 둘과는 다르게 xs라는 메소드가 있는데 인덱스의 레벨을 직접 설정하고 색인을 할 수 있어 하위 레벨 인덱스에 대한 직접 색인이 가능합니다.
예제 파일로 만든 데이터 프레임(df3)을 이용하여 색인을 직접 해봅시다.
# 1. 행에 대한 색인
# 1-1) 상위 레벨 인덱스 'seoul' 색인
df3.loc['seoul',:]
# 1-2) (상위, 하위)를 만족하는 인덱스
df3.loc[('seoul','B'),:]
# 1-3) 하위 레벨 인덱스 'A' 색인
df3.loc['A',:] # 에러 발생
# 1-4) 하위 레벨 인덱스 'A' 색인
df3.xs('A',axis = 0, level = 1)
# 2. 열에 대한 색인
# 2-1) 상위 레벨 인덱스 '냉장고' 색인
df3.loc[:,'냉장고']
# 2-2) (상위, 하위)를 만족하는 인덱스 색인
df3.loc[:,('냉장고','price')]
# 2-3) 하위 레벨 인덱스 'price' 색인
df3.loc[:,'price'] # 에러 발생
# 2-4) 하위 레벨 인덱스 'price' 색인
df3.xs('price',axis = 1,level = 1)
4) 멀티 인덱스 산술연산
1) 축 번호(axis)만 전달 시 : 인덱스 상관없이 각 행별, 열별 연산이 이루어집니다.
예시) df1.sum(0)
2) 축 번호(axis)와 계층(level) 전달 시 : 각 레벨이 같은 인덱스 끼리 묶여 그룹연산이 이루어집니다.
| 입력 | 설명 |
|---|---|
| df3.sum(axis=1,level=0) | 상품 내 항목들의 합 |
| df3.sum(axis=1,level=1) | 두 상품의 가격과 수량 총합 |
| df3.mean(axis=0,level=0) | 지역별 평균 |
5) 컬럼의 인덱스화(set_index)
set_index 메소드는 데이터 프레임의 특정 행을 인덱스화 시키는 메소드입니다. csv 불러오기에서 불러온 데이터 프레임을 통해 어떤 메소드인지 살펴봅시다.
# 1. 불러온 원래 모양
df1 = pd.read_csv(
'read_test.csv',
engine = 'python'
parse_dates = ['date']
)
df1;
# 2. set_index 사용
df1.set_index('date');

6) 인덱스 간 축 치환 및 정렬
멀티 인덱스에서는 각각 다른 계층의 인덱스끼리 치환이 가능합니다. 치환을 위해서는 swaplevel과 sort_index 메소드를 알 필요가 있습니다.
1.swaplevel
df3.swaplevel(0,1) # axis = 0
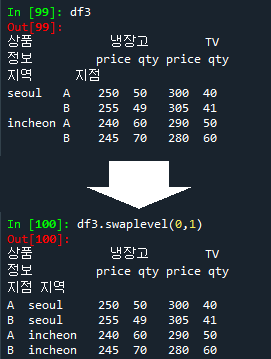
swaplevel 메소드는 서로 바꿀 두 개의 인덱스의 레벨을 적고 뒤에 세번째 인자에 축 번호를 입력하여 인덱스를 바꿀지 컬럼쪽의 순서를 바꿀지 정하면 됩니다.
2.sort_index
그런데 위 코드 실행결과를 보면 원본보다 깔끔하지 않은 것을 확인할 수가 있습니다. 원본은 지역끼리 그룹으로 묶여있는 것으로 보이지만 swaplevel을 실행한 아래는 지점끼리 묶여있지 않은 것을 볼 수 있습니다. 그래서 인덱스 값들의 정렬을 도와주는 sort_index를 사용하면 좀 더 깔끔하게 처리할 수 있습니다.
df3.sort_index(axis = 0, level = 1).swaplevel(0,1)
Out:
상품 냉장고 TV
정보 price qty price qty
지점 지역
A incheon 240 60 290 50
seoul 250 50 300 40
B incheon 245 70 280 60
seoul 255 49 305 41sort_index는 swaplevel과 축 번호와 레벨의 인자 전달 순서가 반대네요. 왜인지는 모르겠습니다. 축 번호를 입력하고 다음에 정렬을 시도할 계층을 리스트나 정수 형태로 적으시면 됩니다. 다음에 swaplevel로 바꾸면 지점별로 그룹으로 묶여있는 것으로 깔끔하게 나옵니다. 그래서 두 메소드는 대부분의 경우에 동시에 사용할 것 같습니다.
복습하면서 동시에 내용을 정리하고 있는데 다루는 내용이 많아질수록 글 쓰는게 점점 쉽지 않은 것 같습니다. 특히 내용을 배치하는 부분에서 어떤 방식이 효율적인지 고민해보게 됩니다. 가장 좋은 배치는 뒤의 내용을 읽을 때 앞에 문단들을 다 읽었을 때 충분히 이해가 되도록 순차적인 구성으로 글을 적는 방식이라고 생각합니다.
올해 상반기에 배웠을 때 실행되는 코드랑 현재 실행되는 코드에 있어서 차이점이 있는 것을 발견했습니다. Python은 오픈소스이기 때문에 모듈의 세부 내용이 수시로 수정이 되는 점을 몸소 느꼈습니다. 그래서 코드를 그대로 가져다 쓰는 방식은 장기적으로 위험하다는 생각이 들었습니다. 직접 코드의 구조를 파악하고 왜 이렇게 실행되는지 살펴보고 나중에 세부적으로 바뀌었을 때 대처하기 위해 Python을 분석 목적 이상으로도 배울 필요성을 느낍니다.
다음 글에는 다양한 예제들을 수록할 예정입니다. 언어 공부는 해당 언어를 자주 사용하고 언어에 익숙해지면서 자연스럽게 된다고 생각합니다. 코드 또한 자주 치다보면 익숙해지는 것 같습니다. 자전거 타는 법 배우듯 한번 익히면 잊지 않았으면 좋겠지만 저같은 일반인은 주기적으로 복습하면서 익숙해지도록 노력해야겠습니다.
Subscribe via RSS
{kind=link}