
mapreduce 맛보기
by Kim
준비 단계
리눅스 마스터에 있는 하둡 설정 관련 파일을 파일질라를 통해 윈도우로 가져옵니다.
-
hadoop-common-2.9.2.jar :
파일 위치 : /usr/local/hadoop/share/hadoop/common
-
hadoop-mapreduce-client-core-2.9.2.jar :
파일 위치 : /usr/local/hadoop/share/hadoop/mapreduce
자바 파일(jar)을 기반으로 실행하기 때문에 자바 문법으로 작성해야합니다. 이클립스를 실행하고 WordCount라는 새 자바 프로젝트를 만듭니다.
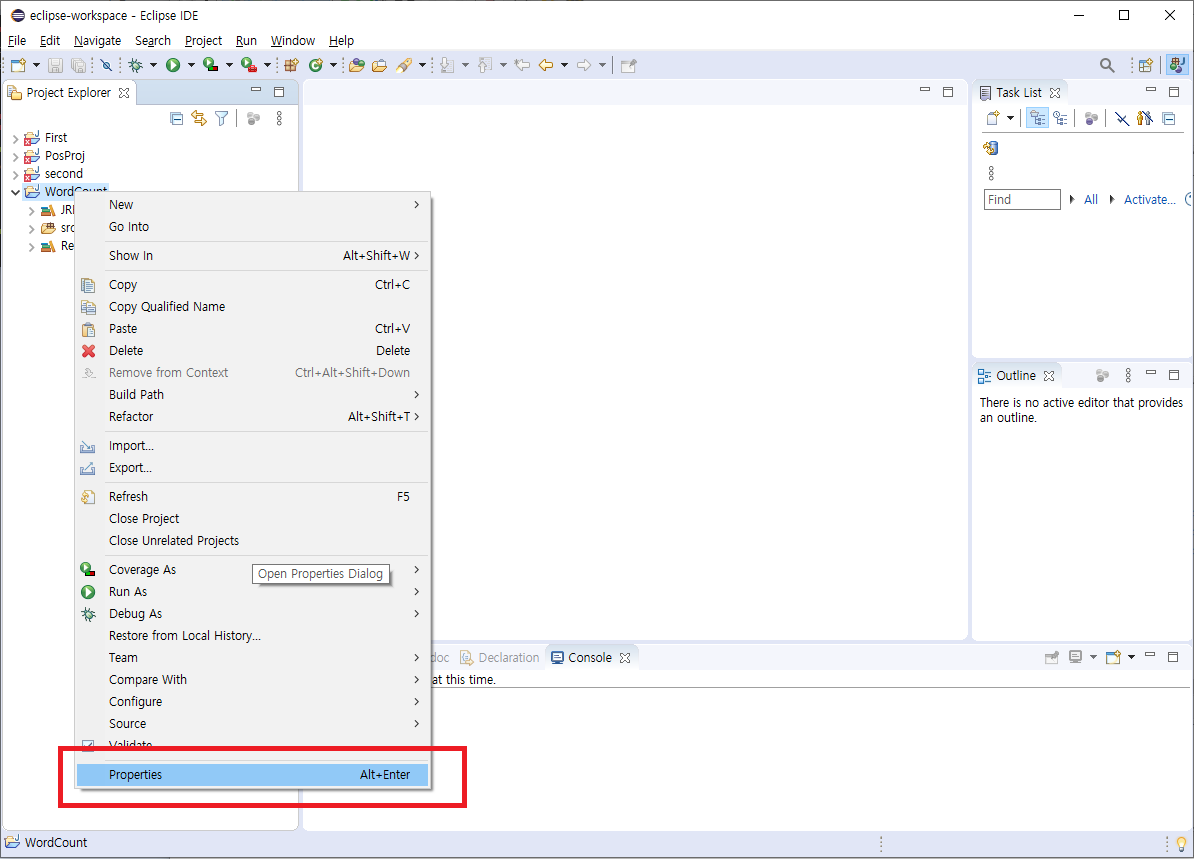
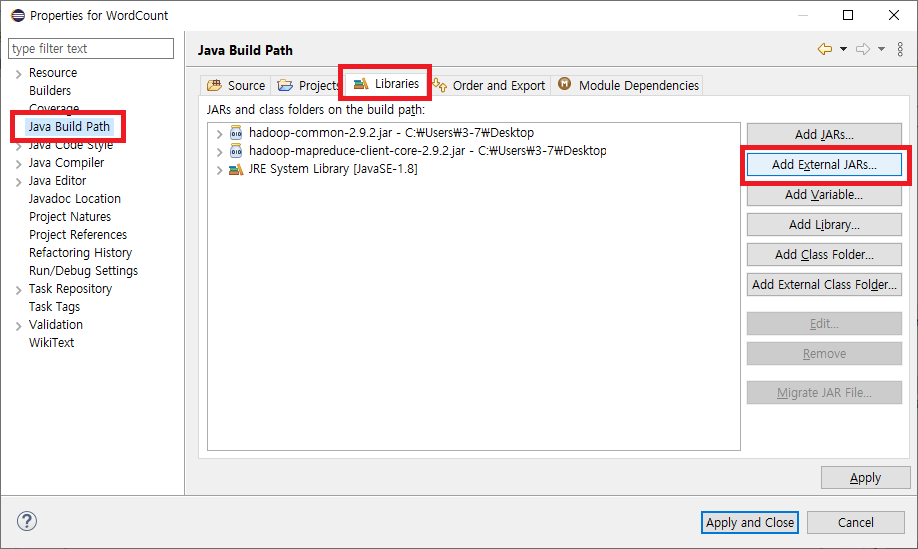
새 자바 프로젝트를 만든 후 Properties(Alt+Enter)를 클릭하면 새 창이 뜨는데 Java Build Path - Libraries - Add External JARs... 로 가서 파일질라를 통해 가져온 하둡 jar 파일들을 불러옵니다. 불러온 후 Apply and Close 버튼을 누르면 라이브러리가 생성되어 하둡 기반의 스크립트 작성을 할 수 있습니다.
환경이 설정되었으면 src를 마우스 오른쪽 클릭하여 com.jin 이라는 package 를 만들고 그 안에 map 이라는 class를 만듭니다.
mapper 만들기
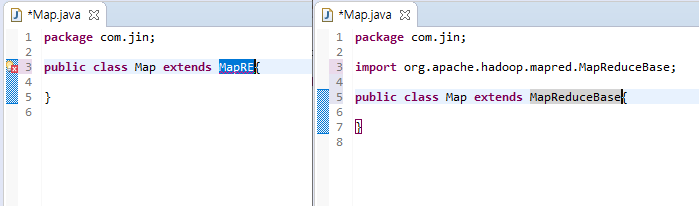
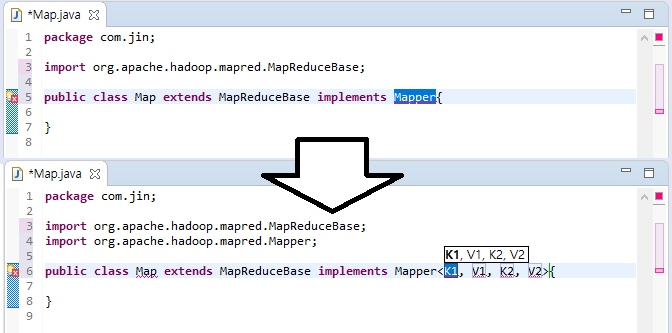
map이라는 이름의 클래스를 만들고나서 extends로 MapReduceBase를, implements로 Mapper를 불러옵시다. ctrl + space_bar 를 이용하여 자동완성 기능을 적극 활용하면 import 작업과 오타방지를 쉽게 할 수 있습니다. 자동완성시 신경써야하는 부분이 있는데 자료형들은 다 org.apache.hadoop.io에 있는 것을 사용해야합니다. 같은 이름인데 다른 라이브러리의 메소드를 가져오게 되면 하둡 실행 시 에러가 발생합니다.
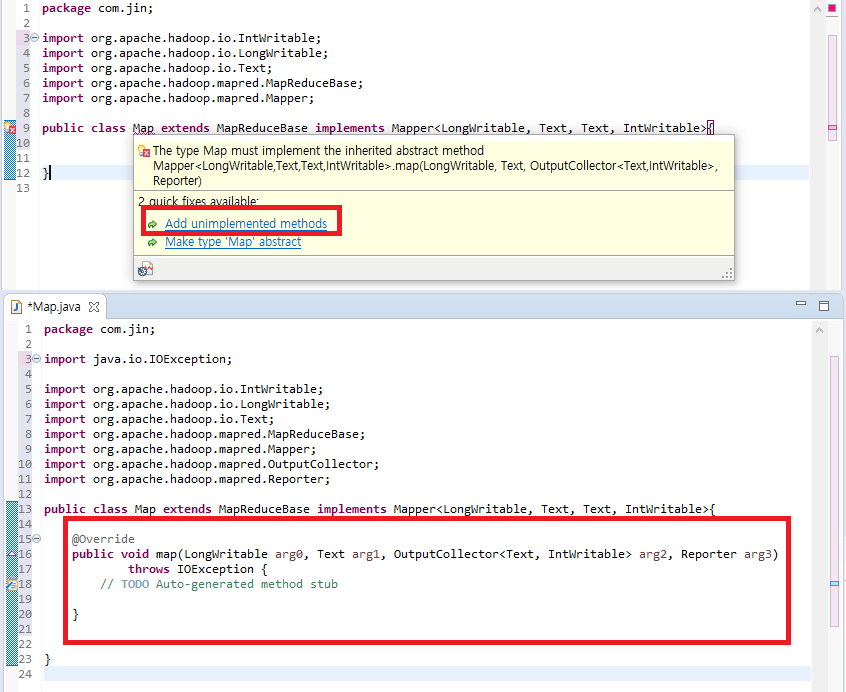
package com.jin;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reporter;
public class Map extends MapReduceBase
implements Mapper<LongWritable, Text, Text, IntWritable>{
@Override
public void map(LongWritable key, Text value,
OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException {
StringTokenizer st = new StringTokenizer(value.toString().toLowerCase(),
" {}|,./\"$%#():;?_\'-");
//st에 데이터가 존재한다면
while (st.hasMoreTokens()) {
Text outputkey = new Text(st.nextToken());
IntWritable outputValue= new IntWritable(1);
output.collect(outputkey, outputValue);
}
}
}StringTokenizer : 문자열을 단어별로 분리하여 배열 형식으로 저장합니다. 첫 번째 인자에 분리할 문자열을 입력하고 두 번째 인자에는 구분자를 ““안에 입력하면 되고 생략이 가능합니다.
ex) value = “단어별로 나눈 데이터가”
st = “단어별로”, “나눈”, “데이터가”
두 번째 인자에서 예를 들면 하이픈(-), 언더라인(_), 빈 칸()을 구분자로 하고 싶으면 “ _-“를 두 번째로 전달합니다.
new StringTokenizer(String) 형식으로 인스턴스 생성 위의 내용은 생성자로 초기화하는 부분입니다.
value : hadoop의 text 형식입니다.
toString() : string으로 변환하는 메소드입니다.
toLowerCase() : 모든 문자를 소문자로 바꿉니다.
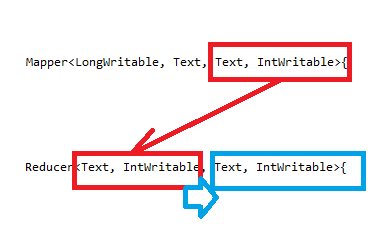
reducer 만들기
mapper에서 보낸 데이터를 받아서 처리를 하는 reducer를 만듭니다.
package com.jin;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
public class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable>{
@Override
public void reduce(Text key, Iterator<IntWritable> values,
OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException {
// TODO Auto-generated method stub
int cnt = 0;
while (values.hasNext()) {
cnt = cnt + values.next().get();
}
output.collect(key, new IntWritable(cnt));
}
}메인 클래스 만들기
지금까지의 진행과정을 하둡으로 보내서 처리를 도와주는 클래스입니다.
package com.jin;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class WordCount extends Configured implements Tool {
@Override
public int run(String[] arg0) throws Exception {
//hadoop에서 실행할 파일 설정
//생성자의 인자로 main class를 전달
JobConf conf = new JobConf(WordCount.class);
//title 설정
conf.setJobName("wordcount");
//출력 형식 지정
//reduce에서 전달되는 출력 key, value 자료형
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);;
//mapper 연결
conf.setMapperClass(Map.class);
//reducer 연결
conf.setReducerClass(Reduce.class);
//입출력 클래스 지정
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
//하둡에서 입출력 경로 설정
FileInputFormat.setInputPaths(conf, new Path(arg0[0]));
FileOutputFormat.setOutputPath(conf, new Path(arg0[1]));
//설정 내용 적용
JobClient.runJob(conf);
return 0;
}
public static void main(String[] args) throws Exception {
//run 멀티스레드를 실행시킴
int exitcode = ToolRunner.run(new WordCount(), args);
System.exit(exitcode);
}
}여기까지 만든 파일을 jar 형태로 export 합니다.
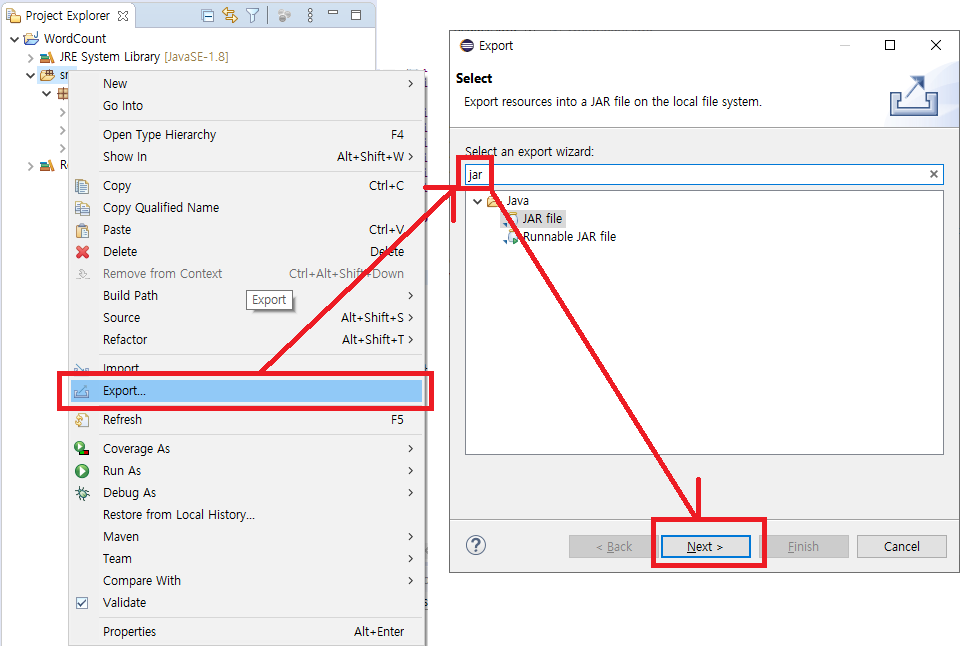
하둡에서 실행할 때 원본 소스는 필요없기 때문에 맨 윗칸만 선택후 jar 파일로 만들면 됩니다.
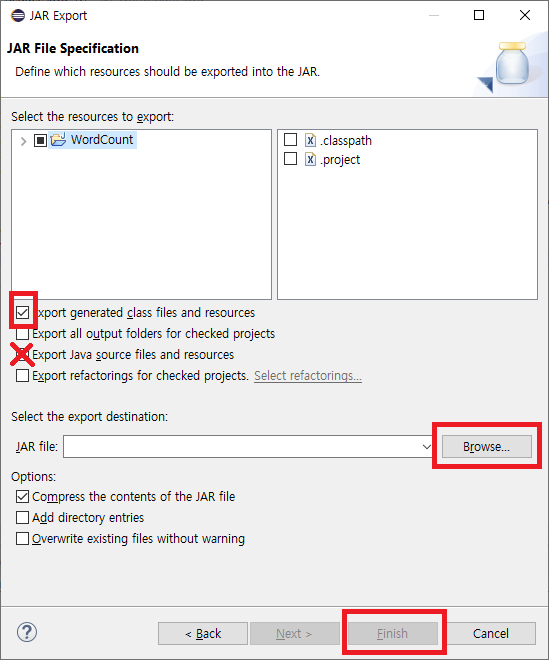
WordCount 실행하기
하둡에 올라와 있는 파일 확인
hadoop fs -ls /
올라와 있는 파일 삭제
hadoop fs -rm -r /input
hadoop fs -rm -r /output
input 폴더 만들기
hadoop fs -mkdir /input
예시 텍스트 파일(CHANGES.txt)을 input폴더에 올리기
hadoop fs -put CHANGES.txt /input
WordCount.jar 실행
hadoop jar WordCount.jar com.jin.WordCount /input /output
Subscribe via RSS
{kind=link}