
하둡 - 완전 분산 모드
by Kim
완전 분산 모드
이전 글에서 만든 싱글 노드는 실습용이었고, 실제로는 싱글 노드로는 사용하지 않고 분산으로 만들어 쓰는 것이 일반적입니다. 이번에는 다음의 스펙으로 분산 모드로 만들어보도록 하겠습니다.
| Master | Slave1 | Slave2 | Slave3 |
|---|---|---|---|
| (JobTracker, NameNode) |
(SecondaryNameNode, DataNode) |
(DataNode) | (DataNode) |
하둡 초기화
완전 분산 모드로 바꾸기 위해 master에 namenode를, slave에 datanode를 두기 위해 master에서 datanode를 제거하였습니다.
shop-dfs.sh
sudo rm -rf /usr/local/hadoop/hdfs/datanode/
sudo rm -rf /usr/local/hadoop/hdfs/namenode/*
datanode가 master에서 지워졌는지 확인해보고 다음으로 넘어갑니다.
ls /usr/local/hadoop/hdfs
> namenode
master 설정
슬레이브(slave)를 만들기 전에 마스터의 기본 설정을 합니다.
host 파일 (/etc/hosts) : ip 대신에 이름으로 접속할 수 있도록 하는 파일. 아래 내용을 입력합시다.
예시
192.168.56.101 master
192.168.56.102 slave1
192.168.56.103 slave2
192.168.56.104 slave3
- core-site 수정
-
localhost로 된 부분을 master로 바꿉니다.
sudo vim /usr/local/hadoop/etc/hadoop/core-site.xml
- mapred-site 수정 (/etc/hosts)
-
localhost로 된 부분을 master로 바꿉니다.
sudo vim /usr/local/hadoop/etc/hadoop/mapred-site.xml
- 하둡 설정파일 저장
-
지금까지 만든 하둡 설정을 저장합니다. /usr/local/hadoop 안에 있는 모든 파일을 hadoop.tar이라는 이름으로 압축합니다.
tar -cvf hadoop.tar /usr/local/hadoop
- 프롬프트 이름 변경[hostname (/etc/hostname)]
-
vim 편집기로 접속 후 기존 값 대신에 master를 입력하고 종료합니다. 재시작 이후에 적용됩니다.
sudo vim /etc/hostname
sudo /bin/hostname -F /etc/hostname
sudo reboot
슬레이브 생성 및 설정하기
이전 글에서 우분투 설치 직후 내보내기로 만든 파일(.ova)을 가져오기를 통해 불러옵니다. putty에서의 접속을 위해 불러온 후 설정에서 네트워크 설정을 아래와 같이 바꿉니다.
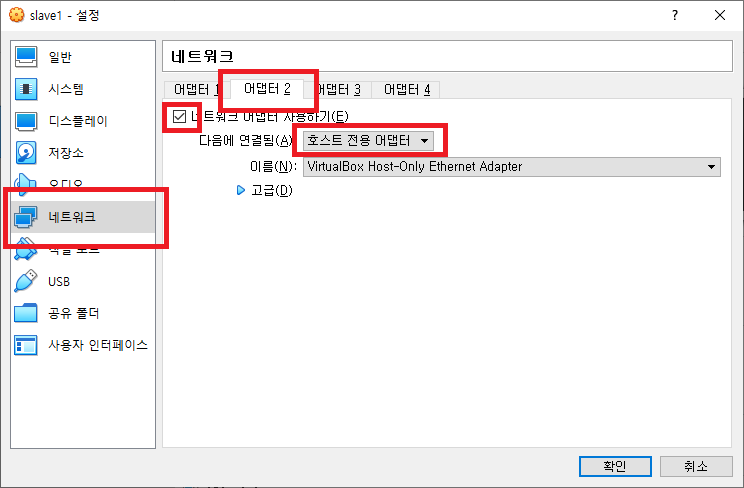
접속후 ssh, vim, jdk를 설치합시다. host 파일도 바꿔줍니다.
인터페이스 파일(/etc/network/interfaces): 슬레이브의 ip를 고정하기 위해 설정합니다. 기존에 있는 address에서 뒷자리만 수정 후 재부팅하면 적용됩니다.
그룹 생성 및 사용자 등록후 우분투를 종료하고 내보내기로 ova파일 생성후 다시 불러오는 방식으로 동일한 슬레이브 3개를 만듭니다.
마스터 설정하기(2)
마스터로 다시 돌아와서 슬레이브의 이름을 적습니다.
sudo vim /usr/local/hadoop/etc/slaves
slave1
slave2
slave3
hdfs-site 파일도 수정합니다. 마스터에 네임노드를, slave1에 세컨더리 노드를 주도록 설정하기 위해서입니다.
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hdfs/namenode</value>
</property>
<property>
<name>dfs.http.address</name>
<value>master:50070</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>slave1:50090</value>
</property>
</configuration>
- slave에 인증키 배포
-
인증키를 배포하게 되면 마스터에서 슬레이브에 접속 시 혹은 명령을 줄 때마다 비밀번호를 일일히 입력하지 않아도 됩니다.
ssh-copy-id -i .ssh/id_rsa.pub manager@slave1
슬레이브에 하둡 설정 배포
위에서 압축한 hadoop.tar를 슬레이브로 보냅니다. 슬레이브마다 각각 압축을 해제 후 tar 파일을 지우는 명령어를 보냅니다. 슬레이브는 총 3개이므로 manager@slave 뒤 숫자만 바꾸셔서 하면 되겠습니다.
scp hadoop.tar manager@slave1:/home/manager
ssh manager@slave1 "cd /home/manager;tar xf hadoop.tar;rm hadoop.tar"
이번에는 각 슬레이브에 들어가서 하둡에 대한 폴더를 만들고 압축을 푼 폴더내용을 이동시키겠습니다. 마찬가지로 파일 이동 후 manager에 폴더 권한을 줍니다.
sudo mkdir /usr/local/hadoop
cd usr/local/hadoop
sudo mv * /usr/local/hadoop/
sudo chown -R manager:hadoop /usr/local/hadoop/
각 슬레이브의 .bashrc에서도 하둡 관련 export 내용을 맨 밑에 추가합니다.
sudo vim .bashrc
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
그리고 datanode 폴더를 만들고 권한 부여 후 hdfs-site.xml를 수정합니다.
sudo mkdir /usr/local/hadoop/hdfs/datanode
sudo chown -R manager:hadoop /usr/local/hadoop/hdfs/
sudo mv * /usr/local/hadoop/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hdfs/datanode</value>
</property>
</configuration>
분산 노드 실행
이제 master로 돌아와서 아래 명령어들을 실행합니다.
hadoop namenode -format
start-all.sh
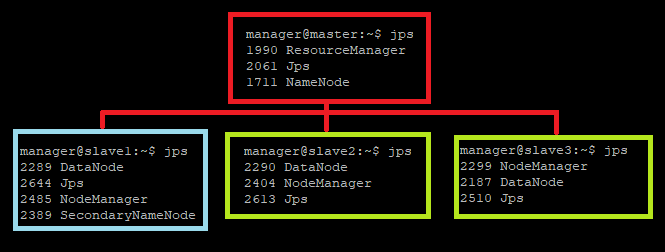
그 다음에 master와 slave1, 2, 3에서 jps를 실행합시다. 정상적으로 작동하면 기본적인 설정은 완료됩니다.
Subscribe via RSS
{kind=link}