
하둡 - 설치 및 싱글 노드 모드
by kim
하둡
하둡은 데이터 분산 처리를 위해 사용하는데 실시간으로 들어오는 소량의 데이터를 처리하는 다른 언어들과 달리 초대형의 데이터를 모아서 한꺼번에 처리하는 데 사용합니다. 같은 작업을 Python으로 한다면 더 간편하고 쉽게 할 수 있지만 테라바이트 이상으로 적재된 데이터를 처리하기는 어렵다고 합니다.
실행을 위한 준비
먼저 가상 머신 버추얼박스(virtual box)를 설치하고 리눅스 OS 우분투(Ubuntu)에서 파일을 받습니다.. 옵션은 크게 건드릴 필요없이 설치 진행하시면 됩니다.
버추얼박스 설치 후 그 위에 우분투를 설치하도록 하겠습니다. 버추얼박스 설치 후 실행을 하면 아래 창이 뜹니다.
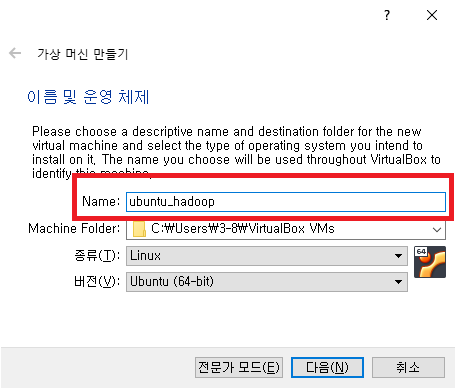
새로 만들기를 뜨면 아래와 같은 창이 뜨게 되는데 Name: 칸에 ubuntu라고 적으면 밑에 종류와 버전이 알아서 맞춰집니다.
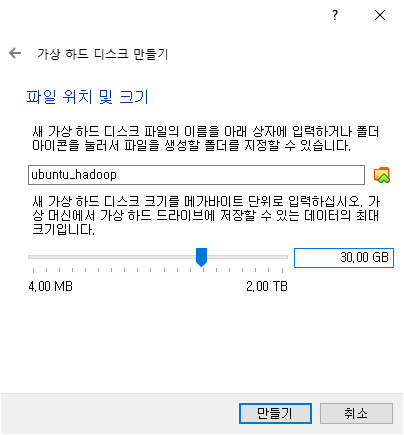
옵션들은 추가적으로 건드릴 필요없이 진행하였으며, 가상 머신에 할당할 RAM은 2MB, 하드 디스크 용량은 30GB로 설정하였습니다.

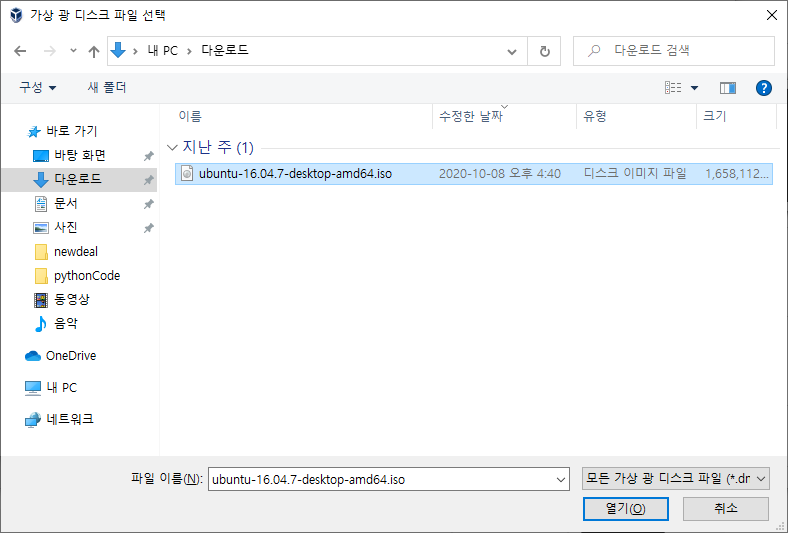
기본적으로 사용할 공간을 만들었으면 공간 위에 아까받은 우분투 파일을 올리도록 하겠습니다.
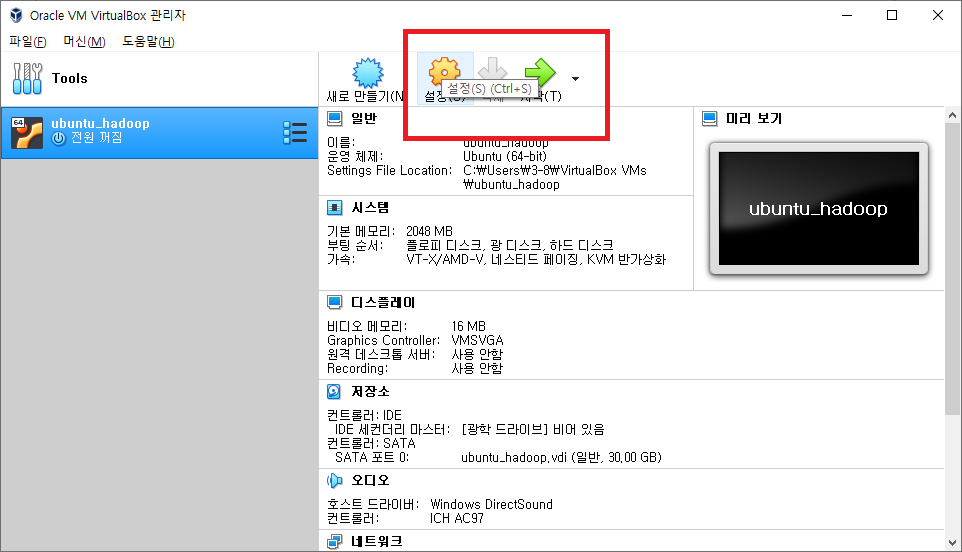
설정에 들어가서 저장소 - 비어 있음 - 우측 파란 버튼에서 파일 선택을 한 후 우분투 파일을 선택합니다.
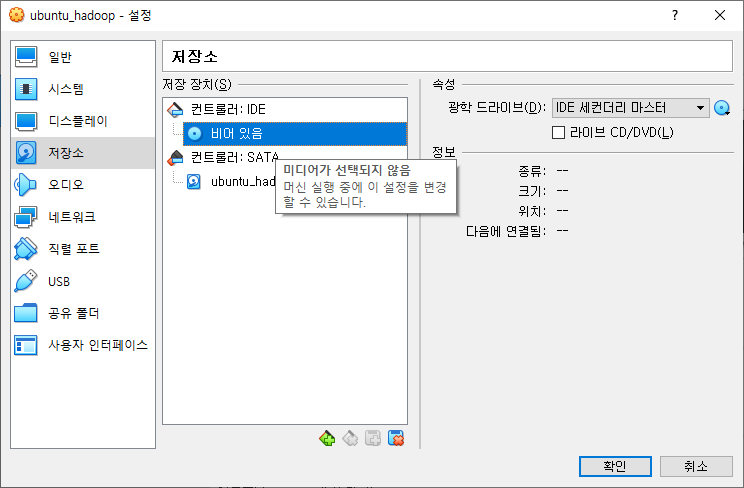
우분투를 실행하기 위한 준비가 끝났습니다. 시작 버튼을 눌러서 가상 머신을 켜봅니다.
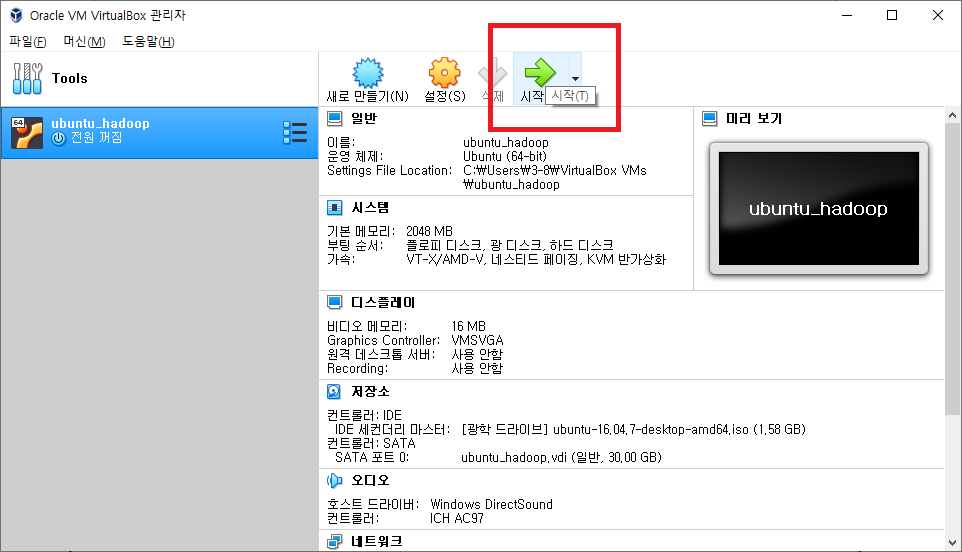
하둡 실행은 버추얼 박스에서 직접 실행할 것이 아니라 푸티(Putty)라는 프로그램으로 연동하여 진행할 것이기 때문에 우분투 초기 설정은 편한대로 진행하면 됩니다.
ifconfig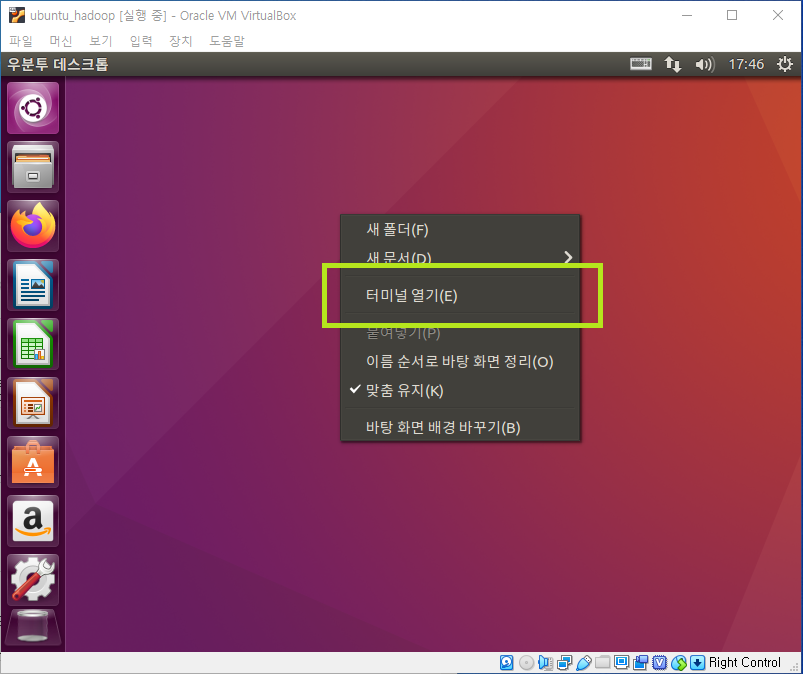
우분투에 하둡 설치
ssh 외부에서 내부로 접근하기 위한 통신을 위해 설치(putty 이용하기 위해) vim (vi 편집기보다 더 향상된 편집기)
세션정보 포트 ssh의 베이스가 22이기 때문
버전 안정화를 위한 업데이트
sudo apt-get update
자바 버전 확인
java -version
jdk 설치 명령어
sudo apt-get install default-jdk -y
jdk : 개발용 툴
jre : 자바를 동작시키기 위한 최소한의 엔진
자바 설치 위치(바로가기)
which java
자바가 실제로 설치되어 있는 위치
readlink -f /usr/bin/java
자바를 프로파일에 보내기
export JAVA_HOME=실제_링크에서_bin_이전
하둡 설치
아파치에 들어가 메인 페이지에서 hadoop을 검색 후 들어가서 다운로드 버튼을 누르고 원하는 버전의 binary를 눌러서 맨 위에 있는 링크를 복사하여 wget으로 리눅스에 설치 합니다.
wget https://downloads.apache.org/hadoop/common/hadoop-2.9.2/hadoop-2.9.2.tar.gz
원래 문법
wget 하둡_링크
다음에 다운로드 받은 하둡 압축 파일의 압축을 해제합시다.
tar zxvf hadoop-2.9.0.tar.gz
폴더를 만듭니다.
sudo mkdir -p /usr/local/hadoop
압축해제한 폴더의 모든 파일을 방금 생성한 폴더로 이동시킵니다.
sudo mv * /usr/local/hadoop/
파일이 다 이동되었는지 ls로 확인한 후 원래 위치로 돌아옵니다.
ls
cd ..
원하는 위치에 하둡 파일을 다 옮겼으니 찌꺼기 하둡 압축 파일과 폴더를 지웁니다. (ha로 시작하는 모든 파일)
rm -rf ha*
사용자 등록 및 소유권
하둡이라는 그룹 만들기
sudo addgroup hadoop
그룹에 manager라는 유저 추가
sudo adduser --ingroup hadoop manager
manager가 어느 그룹에 속하는 지 확인
groups manager
manager에 sudo(시스템 권한)권한 부여
sudo adduser manager sudo
하둡에 속한 manager에 디렉토리 권한 설정(root도 접근 불가)
sudo chown -R manager:hadoop /usr/local/hadoop/
ip설정 고정
버추얼 박스 ip가 증가하는 것을 방지하기 위해 interfaces의 내용에 ip를 고정하는 내용을 추가합니다.
interface 파일 편집기로 열기
sudo vim /etc/network/interfaces
복사할 내용(ifconfig 기반으로 작성)
auto enp0s8
iface enp0s8 inet static
address 192.168.56.101
netmask 255.255.255.0
gateway 192.168.56.1
dns-nameservers 168.126.63.1
bashrc 수정
bashrc를 수정하여 hadoop 명령어를 모든 위치에서 실행가능하게 합니다.
bashrc 파일 편집기로 열기
sudo vim .bashrc
복사할 내용(최하단에 추가))
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
path로 쓴다는 것은 위치가 바뀌어도 명령어를 수행할수 있게 하는 것입니다. 즉, 어느 위치에서도 hadoop 명령을 실행할 수 있게 하는 과정입니다.
환경변수 설정
sudo vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh
sudo mkdir -p /usr/local/hadop/tmp
name 서버 생성
sudo chown -R manager:hadoop /usr/local/hadop/tmp
sudo vim /usr/local/hadop/etc/hadoop/core-site.html
<configuration> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop/tmp</value> </property> <property> <name>fs.default.name</name> <value>hdfs://localhost:62350</value> </property> </configuration>
map-reduce 템플릿 복제해서 사용(하둡 3버전 이상 되면 신경쓰지 않아도 됨)
hdfs-site
sudo mkdir -p manager:hadoop /usr/local/hadoop/namenode
sudo mkdri -p manager:hadoop /usr/local/hadoop/datanode
sudo chown -R manager:hadoop /usr/local/hadoop
sudo vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop/hdfs/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop/hdfs/datanode</value> </property> </configuration>
인증키 생성 및 배포
생성
ssh-keygen -t rsa
배포
ssh-copy-id -i .shh/id_rsa.pub manager@localhost
설정이 끝난 후 리눅스 재부팅을 합니다.
sudo reboot
다시 시작한 후 네임노드 포맷후 start-dfs.sh 실행 후 jps 명령어로 노드를 확인합니다.
hadoop namenode -format
start-dfs.sh
jps
filezila 윈도우의 파일을 우분투로 올리는 기능 hadoop 명령으로 hadoop 서버에 올림
hadoop fs -mkdir -p /wordcount/input
hadoop fs -copyFromLocal /usr/local/hadoop/jar/*.txt /wordcount/input
jar 파일 실행
hadoop jar /usr/local/hadoop/jar/WordCount.jar com.care.WordCount.WordCount /wordcount/input /wordcount/output
문법 설명
hadoop jar [실행파일 위치] [패키지 이름.클래스 이름][입력 위치][출력 위치]Subscribe via RSS
{kind=link}